
Standstill Girl is a turn-based RPG by Uta (Sky Scraper Project) made in RPG Maker 2000.
Alice is a girl who lives in the Land of Time, in the care of a boy named Tiska.
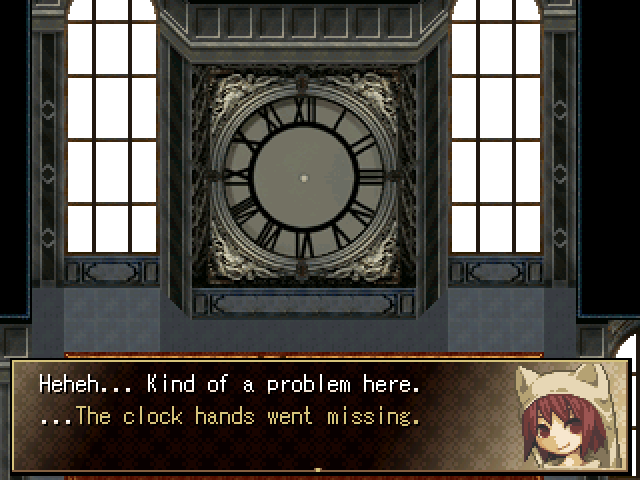
One day, when the hands of the Great Clock are mysteriously scattered, the Land of Life comes to a standstill.
Though it's Tiska's job as a warden of time to recover the hands, Alice can't help but be curious...
(Content Severity: Fairly Mild)
Click here for content warnings.
Slave trading.
Implied abuse.
Implied self-sacrifice.
Download Standstill Girl | (Mirror)
(Chrome may falsely flag the download as malicious, but it's safe to ignore.)
Supported Platforms
The game's engine is made for Windows only, with no native support for other platforms.
The multi-platform EasyRPG Player mimics the behavior of RM2K and RM2K3, but may not always be exact. (Make sure to treat the Data folder as the game folder, not the containing folder.) Also, for Macs, you can try a general-purpose tool like WineBottler.
Troubleshooting
Make sure to extract the game to its own folder instead of running directly from the ZIP file. If you don't do so, any saves made will be lost the next time you run the game.
If you get a DirectDraw error, right-click the EXE, go to Properties, Compatibility, and try other compatibility modes.
If the font doesn't seem correct, download and install the MS Gothic font.
RPG Maker 2000 has some inherent, unfixable control bugs ("automatically moving in a direction" or "no buttons work"). The issues often seem to involve gamepads, or getting "stuck" on an input if Shift and a Numpad key are pressed simultaneously. Thus, try fiddling with gamepads and your keyboard until it fixes. (Reinstalling the game likely won't help.)
If you get "not implemented" errors on or near startup, make sure you have a working sound device (speakers/headphones). It can also occur mid-game if your system doesn't like a particular MP3, in which case, try to delete or replace the file in Music.
You may get "RPG Maker 2000/2003 RTP is not installed" or missing file errors on startup. This can happen if the path contains special symbols, causing files (including RPG_RT.ini) to not be found. Try moving the game folder somewhere without any special symbols in the path.
Screenshots
Guides
Instead of a complete walkthrough, I've made a collection of guides to various aspects of the game. Click or highlight the white boxes to show spoiler text. Many spoilers within.
Guides
Finding Items
Not much point in listing where to get accessories; just destroy all the cogs.
Each "area" (based on the order you go in) has a fixed set of accessories in its cogs.
After you exhaust those, you randomly get either consumable items or Force.
(The items and Force also scale up with the area number.)
Gardening
When you plant a Repose Seed, it starts at 0 Growth and 0 Nutrition, of course.
When you win a battle, seeds in either spot grow.
Growth increases by 1, and Nutrition increases by Force earned divided by 2.
When the plant reaches Growth 10, it can't get any more nutrition.
Nutrition maxes at 999, and actually, its exact value decides what you get.
The last digit of Nutrition decides the item, and the hundredths digit (+1) the quantity.
Up to Growth 4, Repose Seeds remain Repose Seeds.
From Growth 5 to 9, they can be Gerberas (Nutrition ends in 2), Begonias (4), Alstroemerias (6), or Joy Flowers (anything else).
At Growth 10, if the last digit is 6, it's a Fig of Loss; otherwise, it's a Pleasure Fruit.
The last digit is difficult enough to manipulate that it might as well be random.
But there's the info, just in case you wanted to know the exact workings.
Extra Bosses
There are two extra bosses in Farsdale Hospital if you beat all five red Shadelings.
...That's all I'm going to say about that.
Getting Skills
Except for the red Shadeling rewards, all skills are learned at the end of a battle once the conditions for learning it are met. All usage counts are cumulative, not in a single battle.
Guard
Initial skill
Flee
Initial skill
Shock
Initial skill
Brain Blue
Use Shock 25 times
Innocent Rain
Use Brain Blue 20 times, use Southern Cross at least once
Spirit Thorn
Take the battle lecture (or use Shock 40 times)
Southern Cross
Use Spirit Thorn 20 times, then finish a battle with less than 50% LP
Self-Holocaust
Use Southern Cross 10 times, then finish a battle with less than 50% LP
Lacrimosa
Use Nervous Breakdown, Stray Sheep, and Nightmare at least 2 times each
Nervous Breakdown
Have it used against you
Stray Sheep
Have it used against you
Nightmare
Have it used against you
Aura
Use Guard 5 times, have 30 or more max LP (includes accessory bonuses)
Anti-Pain
Use Aura 15 times, have 60 or more max LP (includes accessory bonuses)
Centifulword
Use Anti-Pain 10 times, have 150 or more max LP (includes accessory bonuses)
Spica
Be afflicted by a status ailment 7 times
Constellation Shield
Use Southern Cross 10 times, use Spica 3 times
Psychological
Beat red Shadeling in Malis Residential Area
Element Wall
Beat red Shadeling in Pit Beyond Town
Flam Shout
Beat red Shadeling in Departure for Malis
E. Horrid
Beat red Shadeling in Magnolia, City of Scholars
But the Spell Comes Out Your Eyes
Not a real skill; 1/100 chance of triggering when you use Just Watch
Endings
To easily see all the endings, save after the cutscene where the hands are returned.
Ending A
If you try to enter the door and tell Gulinello you want to take the punishment instead, he won't let you go in ahead of Tiska, so you'll be forced to go talk to Tiska and see Ending B or C.
Instead, say you want to ask Order about forgoing the punishment.
When you reach World's Beginning, say you want to save Tiska. If you don't, you'll be locked onto the other endings (and have to walk all the way back).
Ending B
Talk to Tiska and go through the Garden of Creation.
Watch over him.
Ending C (True)
Talk to Tiska and go through the Garden of Creation.
"..." over him, and then...
Titles
Order gives you various titles in Alice's Backyard. There's not much point to them, though.
She chooses the first one on this list that applies.
- Insufficiently Progressed: Enter the Backyard before the endgame.
- Slow-Footed Girl: Have 30 AGL or less.
- Planter Girl: Harvest every kind of plant.
- Part-Timer Girl: Beat both bonus bosses.
- Fleeing Girl: Flee 50 times.
- Finesse Girl: Get all 21 skills.
- Invincible Girl: Never lose a battle once.
- Achromatic Girl: None of the above apply.
Translation Notes
(These contain spoilers for all aspects of the game. Only read after you've beaten it fully.)